In this article we will check how Kafka stores and organizes the data.
- Kafka records are organized and stored in a Topic.
- Producer applications write data to a Topic and consumer applications read data from a Topic.
- Topics are similar to the folders in a file system and the messages that are sent by producers are stored in the files in that folder. For example if you have a use case to send a weather data to Kafka, you will create a topic called “weather” and the data will be organized under it. Or if the use case is to send coordinates of a moving vehicle , you will create a topic with the name “location-coordinates” and the coordinates will be organized under it.
- A topic is stored as log which is partitioned, replicated and segmented
- In a topic , data is stored as a log and it is partitioned as per the configuration. Each topic can have 1 or more partitions.
- Partition is the unit of parallelism in Kafka. If you create a topic with 5 partition , then a producer can write to all 5 partitions for the topic in parallel.
- Partitions are physical directory with the topic name.
- Replication factor tells us how many copies for each partition should be replicated as the message is written. If you have a replication factor of 3, then up to 2 servers can fail before you will lose access to your data.
- Partition * Replication Factor = Number of replicas
- Replication factor is defined at topic level and Replicas are distributed evenly among Kafka brokers in a cluster.
- Let us create a topic with below configuration and see how this is stored on each of the broker.
- Topic Name : Inventory
- Partition: 5
- Replication-Factor : 3
kafka-topics --create --zookeeper localhost:2181 --topic inventory --partitions 5 --replication-factor 3- If you will check the data folder for the brokers, you will see something like this
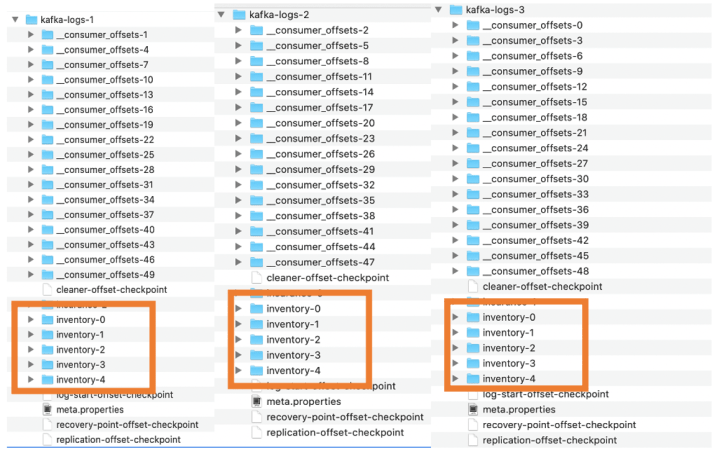
- There are 5 folders created with the topic name. Each of the 5 folders are 5 partitions.
- We mentioned 5 partitions but there are total of 15 folders and that is because we created the topic with 3 replication factor. So while the data is saved in one partition , it gets replicated to other 2.
- Therefore 5 partitions are replicated to 10 more partitions.
- In this setting amongst each partition there is a leader partition and rest are followers. Kafka chooses one broker’s partition’s replicas as leader using ZooKeeper.
- The broker that has the partition leader handles all reads and writes of records for the partition. Kafka replicates writes to the leader partition to followers . Leader partitions are responsible for ensuring that the follower partitions keep their records in sync.
- We can find which is the leader partition and which is follower partition by describing the topic.
kafka-topics --describe --zookeeper localhost:2181 --topic inventory
- From the above output we can see that for Partition 0, Broker 3 has the leader partition and followers are in other brokers. Similarly for Partition 1, Broker 1 has the leader partition.
- Let us now send some data to this topic and see how this data is organized under Topic & Partitions.
- Now before sending the data to the partition, i will make a change to the log segment setting of each of the broker. By default inside the partition folder data is stored in log and the default size of the file is 1 GB. When the data reaches 1 GB size, Kafka creates a new segment of the log file. For this example i changed 1 GB to 1 MB
log.segment.bytes=1000000- If your brokers are running, close the broker and restart the brokers
- Let us now send some data to the topic which was created. i am sending a csv file with insurance data
kafka-console-producer --topic inventory --broker-list localhost:9092 < /Users/rajeshp/data/insurance-sample.csv- If you will open the partition folder , inside it you will find *.log file . When the size of the data crosses 1 MB, then a new segment file is created.

- In each of the log file within a partition, Kafka maintains the order of data. The data offset starts with 0 and it increases. The log file name also starts with the starting offset number it holds for that partition. This is how data is segmented within a partition.
- In order to find data , Kafka requires 3 things- Topic Name, Partition and Offset number.
- Kafka indexes this data and that is stored in .index file . This is also segmented
- There are use cases to fetch data based on timestamp and to support such cases Kafka also creates a time index and this is also segmented .
This was all about how Kafka stores the data . Share your comments and feedback.
Thanks !
Hi Rajesh.. Thanks for detailed explanation.
Thanks.. this helps a lot
Thanks for sharing ..this helped to understand the internals of how Kafka organizes the data. Please share on how Kafka handles rebalancing.